Debugging and Repairing TensorRT Inference
Tracing and fixing a TensorRT FP16 inference bug after fine-tuning a classification model. Full walkthrough: diagnosing ONNX input issues, rebuilding pipelines, validating logits and softmax, and benchmarking model size and speed.

Okay... after retraining a clean 9-label model combining AG News and UK synthetic datasets, initial testing showed strong validation results. However, when exporting the model to TensorRT for FP16 inference, the results diverged heavily from both the PyTorch and ONNX baselines.
This lab focuses on tracing, diagnosing, and fixing the TensorRT quantisation process to ensure the model behaves consistently across deployment targets before we run our previous predictions against it... this could be a little lengthy so grab a ☕ and let's jump in...
📂 Code Repository: Explore the complete code and configurations for this article series on GitHub.
Identifying the issue
After exporting and building the TensorRT FP16 engine, inference produced completely unexpected logits and top-5 predictions.
- PyTorch and ONNX models predicted sensible labels like
health,education, orclimate - TensorRT FP16 engine instead returned
World,Business, andSportswith extremely high confidence
Example prediction on the headline "Cybersecurity breach exposes NHS patient records":
| Model | Top-1 Prediction |
|---|---|
| PyTorch Quantised | health (0.9371) |
| ONNX Quantised | health (0.7760) |
| TensorRT FP16 (original) | World (0.9980) |
Clearly, the TensorRT engine was producing meaningless outputs compared to the original models. The softmax confidence distributions also showed the mismatch...
When facing inference divergence after quantisation, we can apply a structured investigation process:
- Inspect output logits across backends
- Dump and inspect classifier tensors
- Inspect the ONNX model structure
- Validate pre-quantisation ONNX outputs
We can run this against each of the models we produced previously including the interim onnx model that is produced for the fp16 engine quantisation.
Debugging the logits
To start off with, we'll take a look at the logits for each of our models, to do this we can feed a prediction into each of the models and inspect the softmax ratings and raw logits for each model using something like:
# Given a torch model and text run inference and return the logits
def predict_pytorch(model, text):
inputs = tokenizer(text, return_tensors="pt", padding="max_length", truncation=True, max_length=128)
with torch.no_grad():
logits = model(**inputs).logits.squeeze().cpu().numpy()
return logits
# Given a onnx model and text run inference and return the logits
def predict_onnx(session, text):
inputs = tokenizer(text, return_tensors="np", padding="max_length", truncation=True, max_length=128)
input_ids = inputs["input_ids"].astype(np.int64)
attention_mask = inputs["attention_mask"].astype(np.int64)
token_type_ids = np.zeros_like(input_ids, dtype=np.int64)
ort_inputs = {
session.get_inputs()[0].name: input_ids,
session.get_inputs()[1].name: attention_mask,
session.get_inputs()[2].name: token_type_ids
}
logits = session.run(None, ort_inputs)[0].squeeze()
return logits
# Given a tensorrt model and text run inference and return the logits
def predict_tensorrt(engine, text):
context = engine.create_execution_context()
inputs = tokenizer(text, return_tensors="np", padding="max_length", truncation=True, max_length=128)
input_ids = inputs["input_ids"].astype(np.int32)
attention_mask = inputs["attention_mask"].astype(np.int32)
token_type_ids = np.zeros_like(input_ids, dtype=np.int32)
context.set_input_shape("input_ids", input_ids.shape)
context.set_input_shape("attention_mask", attention_mask.shape)
context.set_input_shape("token_type_ids", token_type_ids.shape)
bindings = []
device_buffers = []
for inp in [input_ids, attention_mask, token_type_ids]:
d_in = cuda.mem_alloc(inp.nbytes)
cuda.memcpy_htod(d_in, inp)
bindings.append(int(d_in))
device_buffers.append(d_in)
output_shape = context.get_tensor_shape("logits")
output = np.empty(output_shape, dtype=np.float32)
d_out = cuda.mem_alloc(output.nbytes)
bindings.append(int(d_out))
device_buffers.append(d_out)
context.execute_v2(bindings)
cuda.memcpy_dtoh(output, d_out)
return output.squeeze()These functions will take the approapriate model and a line of text that we pass it, run inference against the model against the text and return the logits.
We can then plot these alongside the softmax confidence scores and produce the following:
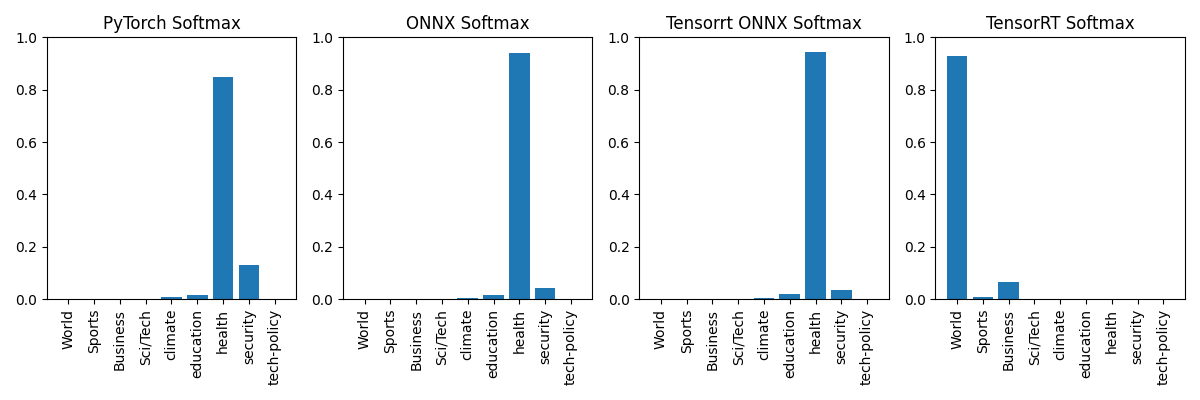
Interestingly, the onnx model we use to produce the FP16 Engine matches our other models that we know are working as expected. So let's plot the raw logits and see if that shows a similar trend...
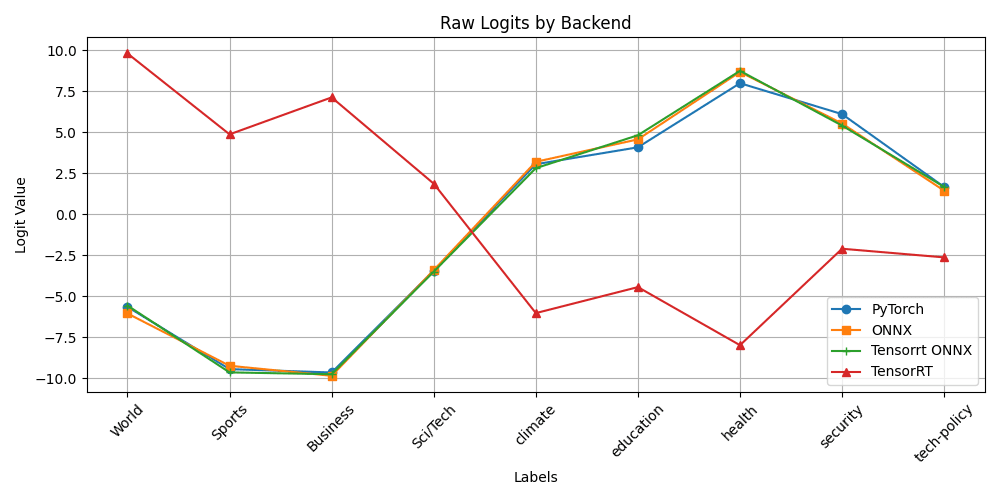
Yes, this confirms the issue is definitely in the quantisation of the onnx model that was created as part of the TensorRT fp16 engine, remember it's a 2-step process (model -> onnx -> fp16_engine).
Sooo what does this mean in terms of our model quantisation... well, let's double check our logs from the lab04/quantisation/tensorrt.py script to see if there's anything I missed in the output ...
[W] [TRT] ModelImporter.cpp:459: Make sure input input_ids has Int64 binding.
[W] [TRT] ModelImporter.cpp:459: Make sure input attention_mask has Int64 binding.
[W] [TRT] ModelImporter.cpp:459: Make sure input token_type_ids has Int64 binding.
DOH!! it turns out these warnings actually tell us what the real issue is ... these warnings tell us that the inputs are bound as int64 inputs but the TensorRT doesn't natively handle these expecting instead int32 inputs... so we need to check the bindings with something like:
# Check ONNX Model bindings
print("\n=== Checking ONNX Model Inputs ===")
onnx_model = onnx.load(ONNX_MODEL_PATH)
for input_tensor in onnx_model.graph.input:
name = input_tensor.name
tensor_type = input_tensor.type.tensor_type
elem_type = tensor_type.elem_type
shape = [dim.dim_value for dim in tensor_type.shape.dim]
dtype_name = onnx.TensorProto.DataType.Name(elem_type)
print(f"[Input] {name}: {dtype_name}")
# Check TensorRT Engine Bindings
print("\n=== Checking TensorRT Engine Bindings ===")
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
with open(TRT_ENGINE_PATH, "rb") as f, trt.Runtime(TRT_LOGGER) as runtime:
engine_data = f.read()
engine = runtime.deserialize_cuda_engine(engine_data)
try:
for i in range(engine.num_bindings):
name = engine.get_binding_name(i)
dtype = engine.get_binding_dtype(i)
is_input = engine.binding_is_input(i)
print(f"{'[Input]' if is_input else '[Output]'} {name}: {dtype}")
except AttributeError:
print("\nERROR: TensorRT engine is corrupted or incomplete. Could not inspect bindings.\n")When we run this we get:
$ python check_bindings.py
=== Checking ONNX Model Inputs ===
[Input] input_ids: INT64
[Input] attention_mask: INT64
[Input] token_type_ids: INT64
=== Checking TensorRT Engine Bindings ===
ERROR: TensorRT engine is corrupted or incomplete. Could not inspect bindings.This proves that our onnx model used for the fp16 engine is instead loading INT64 bindings and that the tensorrt engine is corrupt as we can't read those bindings.
Resolving the issue
Now we know where the issue lies, we can fix it and move on to evaluation and metrics methodologies...
We resolve this by ensuring the onnx model is using a int32 binding set instead of the int64. To do this we can leverage the torch library and force the input_ids, attention_mask and token_type_ids to be int32 as follows before we export the onnx model:
import torch
input_ids = inputs["input_ids"].to(torch.int32)
attention_mask = inputs["attention_mask"].to(torch.int32)
token_type_ids = torch.zeros_like(input_ids, dtype=torch.int32)Once we set this on the interim onnx model and re-run our script we can then validate everything is working as expected ... remember to check the output logs this time...
For the purpose of this lab, I probably went a bit OTT in terms of the rebuild_engine script by running the following steps:
- Build the onnx model
- Validate the onnx logits
- Build the fp16 engine
- Run inference on the fp16 engine
- Plot the Softmax Confidence scores
- Plot the raw logits chart
- Analyse all the outputs and party 🎉
What we now end up with is:
$ python rebuild_engine_32.py
Exporting model to ONNX...
✅ ONNX model exported to: requantised-tensorrt/model.onnx
Validating ONNX model logits...
Building TensorRT engine...
✅ Engine saved to requantised-tensorrt/model_fp16.engine
[Onnx Inference Result]
ONNX Logits: [-5.5632 -9.6391 -9.7508 -3.4967 2.8164 4.8241 8.7513 5.4144 1.674 ]
Top Predictions: [('health', np.float32(0.9445)), ('security', np.float32(0.0336)), ('education', np.float32(0.0186)), ('climate', np.float32(0.0025)), ('tech-policy', np.float32(0.0008))]
[TensorRT FP16 Inference Result]
Logits: [-5.5586 -9.6406 -9.7578 -3.5 2.8145 4.8242 8.7422 5.4219 1.6758]
Top Predictions: [('health', np.float32(0.9438)), ('security', np.float32(0.0341)), ('education', np.float32(0.0188)), ('climate', np.float32(0.0025)), ('tech-policy', np.float32(0.0008))]
>> Saved softmax confidence comparison to: softmax_confidence_comparison.png
>> Saved raw logits line chart to: logits_line_chart.png| Checkpoint | Status |
|---|---|
| ONNX model exported cleanly (input_ids, attention_mask, token_type_ids → int32) | ✅ |
| ONNX logits validated immediately after export | ✅ |
TensorRT FP16 engine built cleanly (no [TRT] warnings) | ✅ |
| TensorRT inference run correctly | ✅ |
| Softmax and logits plots generated | ✅ |
| ONNX and TensorRT logits/softmax match beautifully | ✅ |
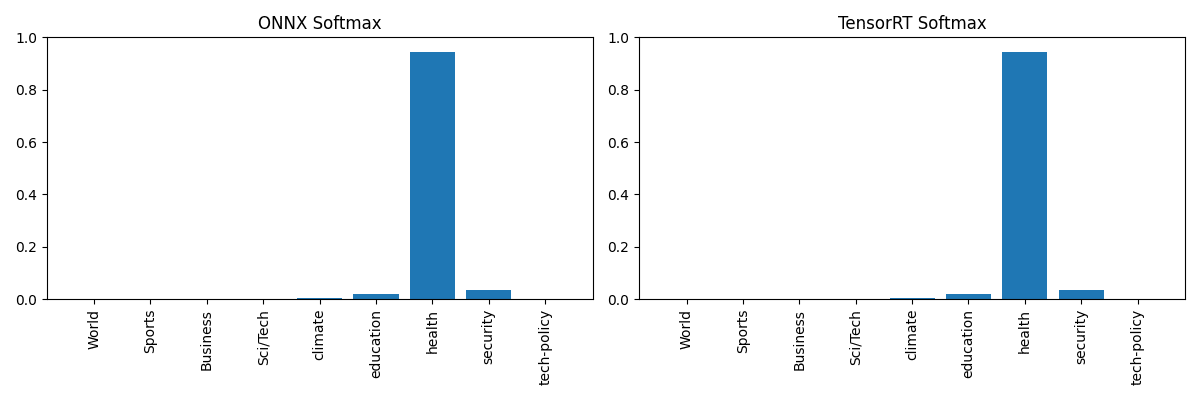
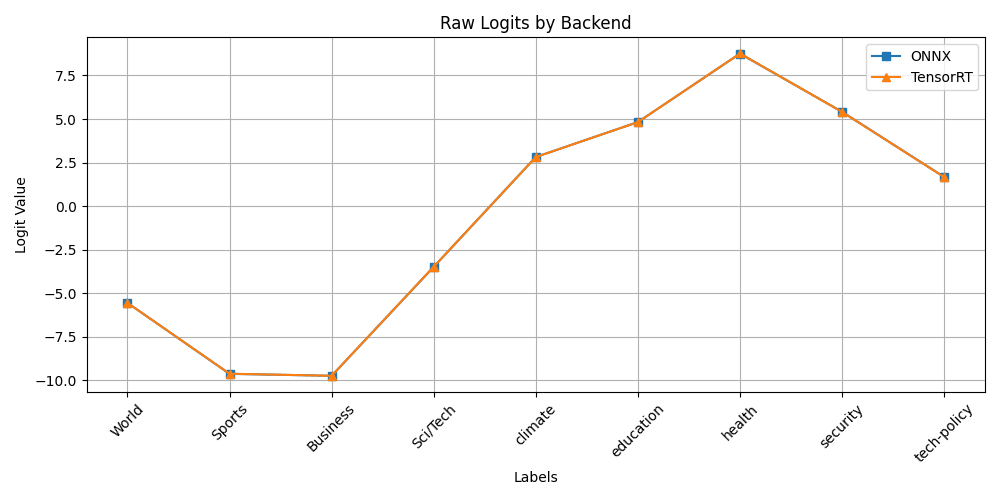
We now have a proper fp16 engine that matches the shape and expected categorisation of our test headline "Cybersecurity breach exposes NHS patient records"... this shows we have indeed identified and FIXED the issue correctly!!!
Key takeaways:
- TensorRT expects int32 inputs by default. Feeding it int64 inputs silently corrupts inference, even if the engine builds successfully
- An ONNX model with wrong input typing will carry its issues into TensorRT, even through FP16 or INT8 optimisation
- Before quantising or deploying, validate that ONNX exports preserve not just graph structure, but also tensor types and final layer mapping
- True debugging needs comparing logits and softmax distributions... not just checking if the top-1 class matches
Now we can revisit our previous prediction and see how this affects the results.
The new results
So in the previous lab we had a prediciton script to help us understand the speed, throughput, accuracy and F-scores for each of our models. The output is now as follows:
Cybersecurity breach exposes NHS patient records:
| Model | Predicted Label | Confidence (Top-1) | Timing (seconds) |
|---|---|---|---|
| Original LoRA | health | 0.9445 | 0.0787 |
| PyTorch Quantised | health | 0.8470 | 0.0625 |
| Optimum ONNX Quantised | health | 0.9395 | 0.0230 |
| TensorRT ONNX Quantised | health | 0.9445 | 0.0616 |
| TensorRT FP16 | health | 0.9456 | 0.1015 |
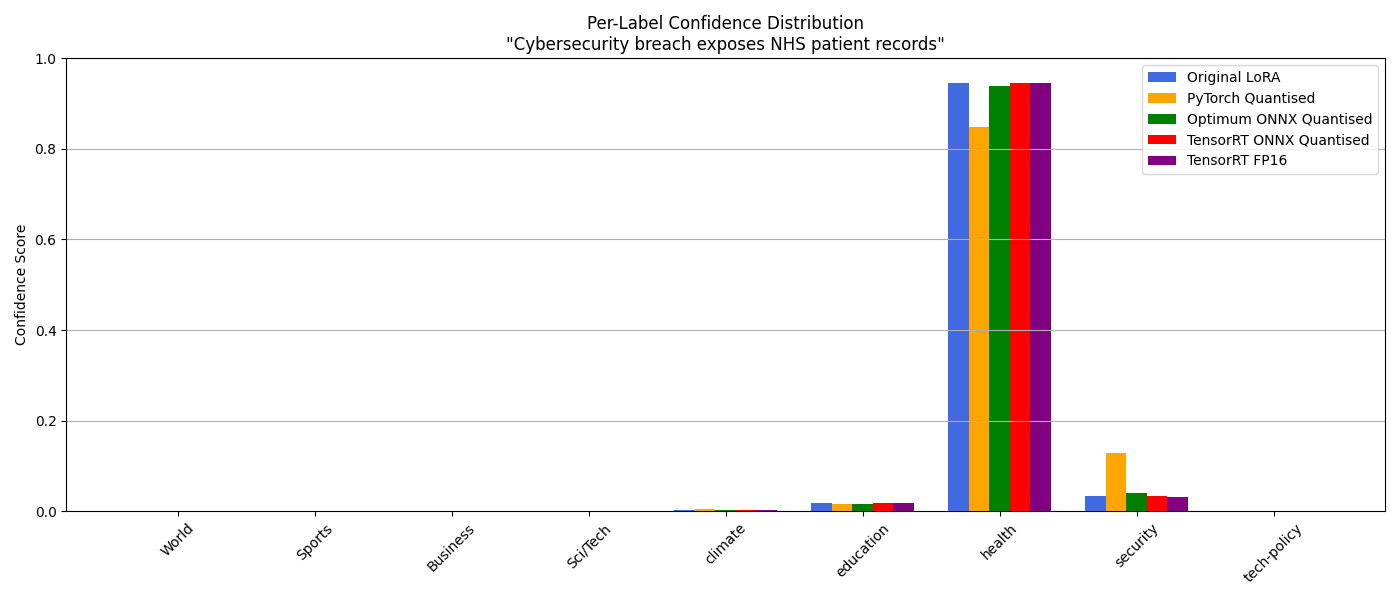
The chart clearly shows that fixing the input types restores consistent logits and softmax distributions across all backends 😃
Despite model weights remaining unchanged, input preparation was standardised across all inference backends (including int32 tensor typing and consistent tokenisation). As a result, predictions across PyTorch, ONNX Runtime, and TensorRT now align more tightly. In this particular case, our headline is now consistently classified as health across all models, reflecting a more reliable decision boundary... I think...
AI tutor program set to roll out in Scottish schools:
| Model | Predicted Label | Confidence (Top-1) | Timing (seconds) |
|---|---|---|---|
| Original LoRA | education | 0.9997 | 0.0625 |
| PyTorch Quantised | education | 0.9996 | 0.0279 |
| Optimum ONNX Quantised | education | 0.9996 | 0.0323 |
| TensorRT ONNX Quantised | education | 0.9997 | 0.0680 |
| TensorRT FP16 | education | 0.9997 | 0.0800 |
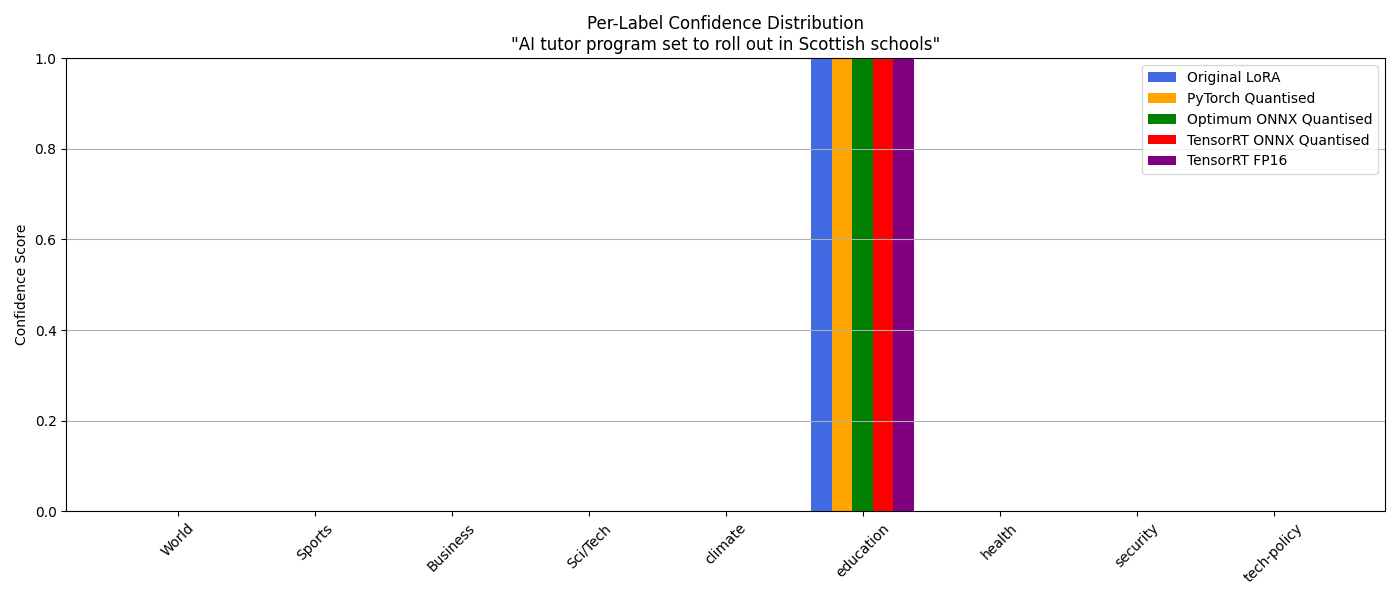
The cahrt shows that all 5 models correctly categorised our headline as "Education" furthering our evidence at resolving the previous issue.
Climate report warns UK cities face extreme flooding by 2030:
| Model | Predicted Label | Confidence (Top-1) | Timing (seconds) |
|---|---|---|---|
| Original LoRA | climate | 0.9992 | 0.0570 |
| PyTorch Quantised | climate | 0.9993 | 0.0404 |
| Optimum ONNX Quantised | climate | 0.9994 | 0.0158 |
| TensorRT ONNX Quantised | climate | 0.9992 | 0.0666 |
| TensorRT FP16 | climate | 0.9993 | 0.0746 |
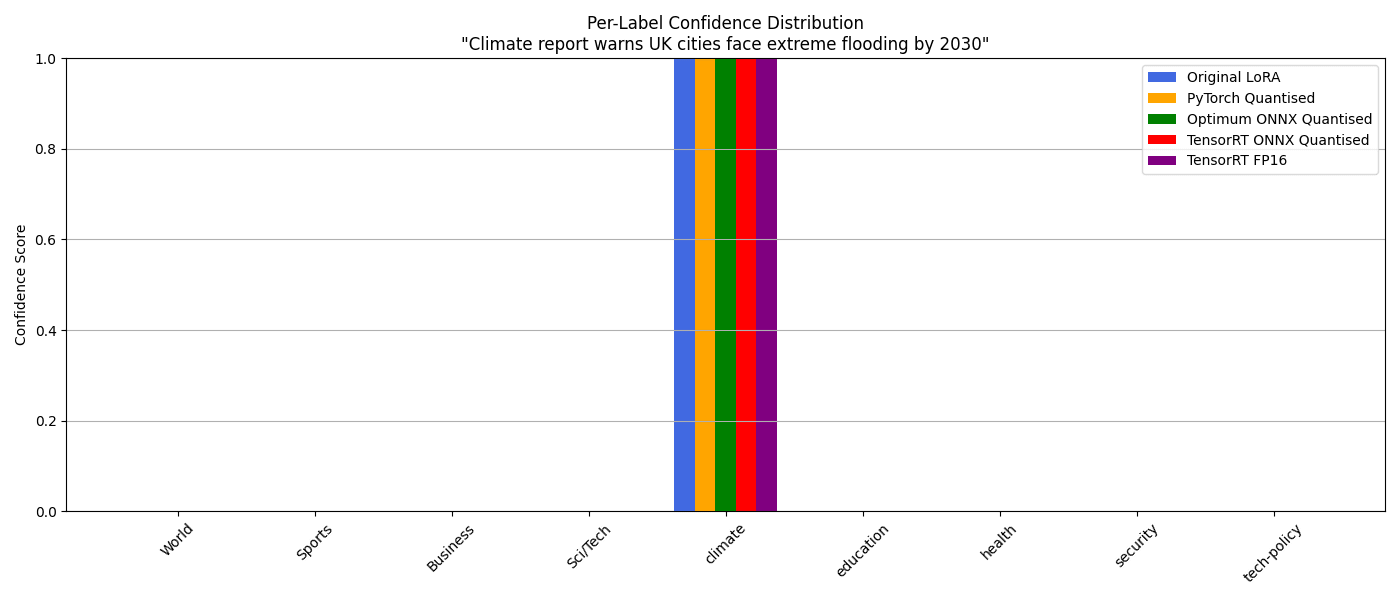
This chart shows that all of the models correctly classified this headline as "Climate" ... the word climate being in the headline probably helped 😆
Performance and Sizings
In terms of overall performance, we actually see that for our particular model and dataset, Optimum Onnx actually out performs the TensorRT FP16 model by quite some way ... this is probably due to the time it take to load the model into the GPU so a future test that loads the model up front and runs inference against the model once it's running would seem like a logical step.
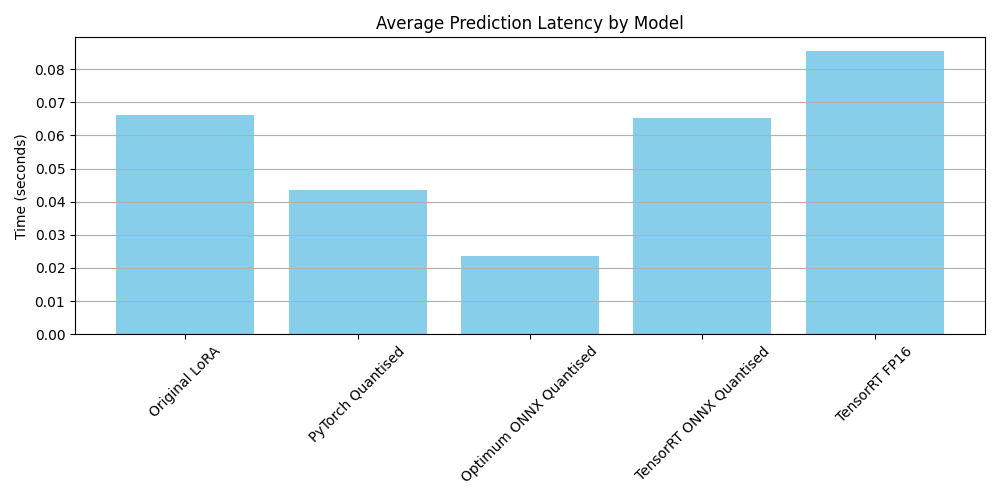
Size wise we now have:
| Model | Size | Compression | Inference Target |
|---|---|---|---|
| Original LoRA | 418MB | Baseline | Full-precision GPU/CPU |
| PyTorch Quantised | 174MB | 58% smaller | Fast CPU |
| Optimum ONNX Quantised | 106MB | 75% smaller | Super-fast CPU |
| TensorRT ONNX INT32 | 213MB | 49% smaller | Pre-TensorRT build |
| TensorRT FP16 | 418MB | Same size | Fastest GPU |
Conclusion
We have successfully identified and resolved the issue faced in the TensorRT fp16 engine and have re-run our previous tests.
Now we have working models, speeds, throughput and accuracy scores we can confidently say ...
- if you want high compression with fast CPU inference i.e. edge environments, on-device modelling... then leverage Optimum ONNX quantised models
- if you're running it in a GPU based enviroment then leverage TensorRT FP16 (remembering to get the input types right)
Next Time
... or can we? What about larger models and the same metrics? What about a 7B model .. can this quantised to run on an intel chipset as well as a GPU chipset? find out next time or we can explore deploying or new models in front of an API to see how they perform once deployed ... let's see where this goes.