Deep Learning: Training Our First Model
Discover how we fine‑tuned BERT on the AG News dataset with PyTorch’s efficient data pipelines, mixed‑precision training, and AdamW. Achieve 94.6% accuracy, explore a confusion matrix of class mix‑ups, and grab the ready‑to‑use model artefacts.

In our previous lab, we explored classic machine learning by training a decision tree on the Iris dataset... learning how to clean data, select features, fit a model, and evaluate its accuracy. This time, we're advancing to a transformer‑based NLP with BERT on the AG News dataset.
First, I needed to make sure Python could access my GPU. Here’s a quick script:
import torch
print(torch.cuda.is_available())
print(torch.cuda.get_device_name(0))Essentially, all this does is to leverage the torch library to check if the CUDA library is available and if it is what the device name is.
If you are struggling to get the cuda library to return "True" and your GPU name, then I'd recommend:
- taking a look at https://developer.nvidia.com/cuda-downloads
- Check out some of the awesome videos on YouTube on "Setting up CUDA"
- Leverage AI to help you run AI ... ChatGPT and Gemini are my friends at the moment
So, now we've validated our environment can indeed access our GPU it's time to start making it do something other than render game frames 🙈
📂 Code Repository: Explore the complete code and configurations for this article series on GitHub.
Training the Model
The plan is to build a news headline classification service from the BERT Base model (smaller and easier to work with) that given a bunch of headlines will help categorise them into the right categories
Okay, firstly, I wanted to map out the flow of what we needed to do... basically we'll load AG News dataset, tokenise and batch it, load BERT onto the GPU, train for five epochs, then evaluate and save our model.
Loading the AG News Dataset
Let's get started by loading the dataset from Hugging Face, luckily for us there's a dataset module in pip that we can leverage for just this purpose 🍀
from datasets import load_dataset
# load the dataset and extract the text and labels
dataset = load_dataset("ag_news")
train_texts = dataset['train']['text']
train_labels = dataset['train']['label']
So what we do here is pull in the ag_news dataset and load it into our dataset, the structure of which provides 2 sets of data ... the text and the labels associated with the headlines.
Tokenising our dataset
Next up we need to tokenise our text which is done using the bert-base-uncased tokeniser which matches the model we'll be training against.
# load the tokeniser and generate our tokens
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
tokens = tokenizer(
train_texts,
padding=True,
truncation=True,
return_tensors="pt"
)Here we're asking BERT's tokeniser to pad and truncate each example so that every batch has the same length which is crucial for faster processing.
NB: a tokeniser is essentially a translation mechanism that converts words to numbers, the models understand numbers; see what-is-tokenisation for more information.
Next up is to convert our set of tokens into a TensorDataset (the bundle):
# convert our lables to a tensor and build the dataset bundle
labels = torch.tensor(train_labels)
dataset = TensorDataset(tokens['input_ids'], tokens['attention_mask'], labels)
train_loader = DataLoader(dataset, batch_size=32, shuffle=True, num_workers=4, pin_memory=True)For this part, we're setting up the dataset and ensuring the training data loader is configured correctly from the labels and the tokenised outputs.
NB: A TensorDataset bundle of tensors from the tokenisation phase that allows PyTorch to treat them as a single unit; see what-is-a-tensordataset for more information.
Load the optimiser and train the model
Sweet, now we're ready to create our model and kick off the training... here's one I made earlier 😆
# define our model as bert-base-uncased
model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=4)
# train it with our dataset :)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
optimizer = AdamW(model.parameters(), lr=5e-5)
scaler = GradScaler()
model.train()
for epoch in range(5):
epoch_loss = 0
print(f"\n🚀 Epoch {epoch+1}")
for batch in tqdm(train_loader, desc=f"Epoch {epoch+1}"):
input_ids, attention_mask, labels = [x.to(device) for x in batch]
optimizer.zero_grad()
with autocast(device_type=device.type):
outputs = model(input_ids, attention_mask=attention_mask, labels=labels)
loss = outputs.loss
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
epoch_loss += loss.item()
avg_loss = epoch_loss / len(train_loader)
print(f"✅ Epoch {epoch+1} complete — Avg Loss: {avg_loss:.4f}")
Once we have everything set up, training proceeds in five full iterations (or epochs) over the AG News dataset. During each pass, the examples are grouped into small batches and sent to the GPU for speed. The model makes predictions on each batch and computes a loss value measuring its error. Using mixed‑precision arithmetic, that loss is back‑propagated through the network to calculate gradients, which the optimiser then uses to tweak the model's internal weights.
Meanwhile, the code keeps a running sum of all the loss values so that, once every batch in the epoch has been processed, it can divide by the number of batches and report an average loss... letting us see how training is improving (or not) from one epoch to the next.
Evaluating the Model
Once training wrapped up, we ran our fine‑tuned BERT on the held‑out test set and achieved 94.6% accuracy. To see where the model still stumbled, we plotted the confusion matrix:
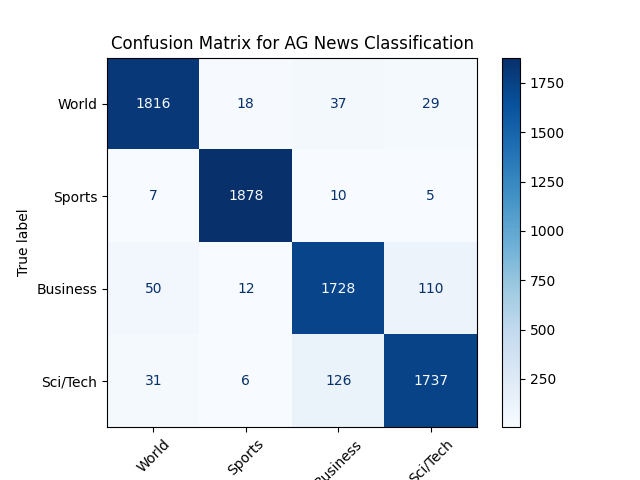
From the matrix, it's clear that "Business" and "Sci/Tech" headlines occasionally get mixed up... around 110 "Business" examples were misclassified as "Sci/Tech", and about 126 "Sci/Tech" as "Business"... likely because tech articles often mention companies and markets.
This being said, "World" and "Sports" labels remain highly reliable, each with fewer than 60 total errors out of nearly 1,900 samples.
Next Time...
Next time, we'll look into supplementing our model with some new categories through LoRA training and we'll look at techniques for making our models faster and more optimised.
Concepts Deep Dive
If you're interested in understanding a bit more about tokenisation, what a tensor dataset is or how an optimiser works then check out the following sections .. they are a bit more involved though but hopefully consumable...
What is Tokenisation?
The tokeniser is like a translator... it takes human-readable text and turns it into something the model understands: numbers. Specifically, it:
- Splits text into smaller known pieces called subwords or Wordpiece tokenisation (e.g., "unbelievable" → "un", "##believ", "##able")
- Maps each subword to a **token ID** from a pretrained vocabulary
- Adds **special tokens** like `[CLS]` (start) and `[SEP]` (end)
- Applies **padding** to make all sequences the same length
- Outputs a tensor dictionary with:
- `input_ids`: token IDs
- `attention_mask`: 1's for real tokens, 0's for padding
This step ensures the text is aligned with the way the pretrained BERT model was trained... it's the bridge between language and math.
Example: Sentence "Playing video games is fun."
| Step | Result |
|---|---|
| Raw input | Playing Video Games is fun. |
| Lowercased | playing video games is fun. |
| WordPiece tokenization | [CLS], play, ##ing, video, games, is, fun, ., [SEP] |
| Token IDs | [101, 2378, 1475, 3040, 2267, 2003, 7023, 1012, 102] |
| Attention mask (1 = real token) | [1, 1, 1, 1, 1, 1, 1, 1, 1] |
| Token type IDs (all single‑sentence) | [0, 0, 0, 0, 0, 0, 0, 0, 0] |
- [CLS] (101) and [SEP] (102) wrap the sequence for BERT classification
- play → 2378; ##ing → 1475 splits the verb into subwords
- video (3040) & games (2267) are in‑vocab tokens
- Attention mask flags all tokens as real (no padding)1
- Token type IDs are all zeros since this is a single‑sentence input
1Padding is applied when we set a fixed lengths for tokens, essentially fills out the rest with zeros e.g. a fixed length of 10 would produce [1, 1, 1, 1, 1, 1, 1, 1, 0, 0]
What is a TensorDataset?
After tokenisation, we have multiple tensors: `input_ids`, `attention_mask`, and `labels`.
A TensorDataset simply bundles these together so PyTorch can treat them as a single unit, effectively like rows in a spreadsheet:
- Each item = one row of input → (`input_ids`, `attention_mask`, `label`)
- When paired with a `DataLoader`, it supports batching, shuffling, and efficient iteration
This format is essential for PyTorch to feed batches into the model during training.
What is an Optimiser?
An optimiser in deep learning is the algorithm that adjusts your model’s parameters (its weights and biases) so that it learns to make better predictions. Think of training as a teacher giving the model "graded homework" (the loss), and the optimiser as the student's strategy for revising its answers to improve next time.
So why do we need one... well, in a nutshell:
- Loss tells us how bad we did: After a forward pass, we compute a loss (e.g. cross‑entropy for classification)
- Gradient tells us which way to move: Backpropagation computes the gradient of the loss with respect to each parameter, indicating how a small change in that parameter would affect the loss
- Optimiser steps in: It uses those gradients to decide how much and in which direction to update each parameter
| Optimiser | Key Idea | Pros | Cons |
|---|---|---|---|
| SGD | θ ← θ − η · ∇θL (vanilla gradient descent) | Simple, easy to implement | Can be slow to converge; sensitive to learning rate |
| Momentum | Accumulates an exponentially decaying average of past gradients to "smooth" updates. | Speeds up convergence in consistent directions | Adds extra hyperparameter (momentum) |
| Adam | Combines momentum + adaptive learning rates per parameter (estimates first & second moments of gradients). | Fast convergence, works out of the box for many tasks | More memory; sometimes over‑fits if not regularized |
| AdamW | Variant of Adam that decouples weight decay (L2 regularization) from the gradient update. | Better generalization; preferred for transformers like BERT | Slightly more complex hyperparameter tuning |