Quantisation in Deep Learning: A Practical Lab Guide
Explore INT8 and FP16 quantisation of a LoRA-fine-tuned BERT across PyTorch, ONNX Runtime and TensorRT. Compare model size, inference latency and nine-way F1 to discover which workflow best balances accuracy and performance on CPU and GPU deployments.

Modern NLP models often push the envelope on accuracy but that extra precision comes at the cost of larger disk footprints, higher latency, and greater energy consumption. In this lab, we take a single LoRA‑fine‑tuned BERT classifier (trained on AG News plus nine custom categories) and ask: how far can we shrink and accelerate it before its 9‑way F1 score starts to slip?
Rather than offer a one‑size‑fits‑all trick, we'll explore two precision targets: full 8 bit integer (INT8) and half precision floating point (FP16); then run each through three popular runtimes. By the end of this exercise, we'll see exactly how model size (in megabytes), inference latency (milliseconds per sample), and classification accuracy shift depending on the quantisation workflow you choose.
Precision vs. Performance
For years, FP32 reigned supreme: it's straightforward, well-supported everywhere, and delivers rock-solid accuracy. But on resource-constrained devices i.e. mobile CPUs, edge TPUs, or shared cloud GPUs...that extra headroom can be the difference between an instant response and a frustrating lag.
- INT8 quantisation replaces 32-bit floats with 8-bit integers. Weights shrink by 75%, inference math becomes leaner, and many CPUs can execute integer kernels far more efficiently than floats
- FP16 (half-precision) keeps your computations in floating point but halves the bit-width. On NVIDIA GPUs, Tensor Cores can crank through FP16 ops dozens of times faster than FP32, often with negligible accuracy loss
Our objectives in this lab is twofold:
- Empirical - measure exactly how our LoRA-BERT behaves under INT8 and FP16 in three runtimes
- Conceptual - understand the trade-offs and workflows behind each quantisation paradigm
📂 Code Repository: Explore the complete code and configurations for this article series on GitHub.
PyTorch Dynamic INT8 (CPU)
We begin with the easiest path: dynamic post-training quantisation in PyTorch. With a single API call, all the Linear layer weights collapse from float32 → int8; activations are quantised on the fly, so there's no calibration step required... in essence...
from torch.quantization import quantize_dynamic
quantized_model = quantize_dynamic(
model, # your pretrained LoRA-BERT
{torch.nn.Linear}, # layers to target
dtype=torch.qint8 # convert weights to 8-bit ints
)
The result is a model that is roughly one‑quarter of its original size and uses efficient integer kernels under the hood. You may see a fractional drop in 9‑way F1 scores... typically under 1%... but for many NLP tasks this trade‑off is well worth the speed and memory savings.
ONNX Runtime Dynamic INT8 (CPU & Cloud)
Next, we leverage the same "zero-calibration" style in ONNX Runtime which is ideal for teams that deploy across languages or need C#/C++ inference. After exporting your FP32 model to ONNX, a near-identical call transforms it to INT8:
# step 1: Export to ONNX
main_export(
model_name_or_path=model_path,
output=str(export_path),
task="text-classification",
opset=17
)
# step 2: Quantise with ONNX runtime
onnx_model = export_path / "model.onnx"
quantized_model = export_path / "model_quantised.onnx"
quantize_dynamic(
model_input=str(onnx_model),
model_output=str(quantized_model),
weight_type=QuantType.QInt8
)What we do here is export our previous lora trained model as an ONNX runtime model then we carry out the Dynamic INT8 quantisation on the runtime model. In essence, what's happening under the hood here is:
- ONNX Export - We use
optimum.exporters.onnx.main_exportto convert our LoRA-fine-tuned BERT (9-label) from the Hugging Face format into anopset-17 ONNX graph. This step preserves your model's structure and weights in a cross-platform IR (intermediate representation) - Dynamic INT8 Quantisation - The call to
quantize_dynamic(…, weight_type=QuantType.QInt8)
- Converts all weights in ops like
Gemm(general matrix multiplies, i.e. your linear layers) from float32 → int8 on disk - Leaves activations to be quantised on the fly at inference time
- Writes out a new ONNX file (
model_quantised.onnx) that, when loaded by ONNX Runtime, will automatically dispatch to integer kernels
In practice, the ONNX Runtime lets us take our INT8‐quantised model out of Python and run it anywhere i.e. with support for C#, C++, Java and more... we're not tied to a specific runtime. It guarantees that the accuracy and performance you observed during PyTorch's dynamic quantisation carry over unchanged, thanks to its highly optimised integer kernels on both CPU and GPU.
Finally, because the ONNX Runtime is a standard inference engine in many production environments, it plugs seamlessly into containerized microservices or managed ML platforms like Azure ML and AWS SageMaker, or running entirely in-house on Kubernetes with Kubeflow and KServe... turning our simple one-liner quantiser into a battle-tested deployment artifact.
TensorRT Mixed-Precision FP16 (GPU)
When you need blistering GPU throughput, NVIDIA's TensorRT and its Tensor Cores shine with half-precision math. In this step we export our 9-label LoRA-BERT to ONNX and then compile it into an FP16 TensorRT engine:
# step 1: Export to float32 ONNX
model = AutoModelForSequenceClassification.from_pretrained(model_dir).eval()
tokenizer = AutoTokenizer.from_pretrained(model_dir)
dummy = tokenizer(
"Example headline for export",
return_tensors="pt", padding="max_length",
truncation=True, max_length=128
)
torch.onnx.export(
model,
args=(
dummy["input_ids"],
dummy["attention_mask"],
dummy.get("token_type_ids", None)
),
f=onnx_path.as_posix(),
input_names=["input_ids","attention_mask","token_type_ids"],
output_names=["logits"],
dynamic_axes={
"input_ids": {0: "batch"},
"attention_mask":{0: "batch"},
"token_type_ids":{0: "batch"}
},
opset_version=17
)
print(f"✅ ONNX model exported to: {onnx_path}")We first serialise our FP32 LoRA-BERT into an ONNX graph, preserving the dynamic batch dimensions and tokenisation details so it can accept any batch size up to 128 tokens.
# step 2: Build FP16 TensorRT Engine
trtexec_cmd = [
"trtexec",
f"--onnx={onnx_path}",
f"--saveEngine={engine_path}",
"--fp16",
"--minShapes=input_ids:1x128,attention_mask:1x128,token_type_ids:1x128",
"--optShapes=input_ids:1x128,attention_mask:1x128,token_type_ids:1x128",
"--maxShapes=input_ids:1x128,attention_mask:1x128,token_type_ids:1x128",
]
result = subprocess.run(trtexec_cmd, capture_output=True, text=True)
print("trtexec stdout:\n", result.stdout)
print("trtexec stderr:\n", result.stderr)
if engine_path.exists():
print(f"✅ TensorRT engine created at: {engine_path}")
else:
print("❌ TensorRT engine was NOT created. Check trtexec output above.")NB: For this bit I'm leveraging a CLI call out to the main NVIDIA TensorRT (version 10.9.0.34) library to convert our engine (the Python libs were erroring on me for some reason and this was the easiest alternative).
Sooo by passing --fp16 to trtexec, TensorRT leverages NVIDIA Tensor Cores to run all matrix multiplies and convolutions in half-precision, cutting memory in half and often doubling or tripling throughput on modern GPUs.
By taking this approach, we gain a GPU-optimised engine without any need for activation calibration or extra training loops. The only prerequisites are an up-to-date TensorRT toolkit and a compatible NVIDIA GPU. The benchmarking should so that this FP16 engine delivers some of the highest throughput of all three workflows, making it the go-to choice whenever our inference is GPU-bound and we can tolerate half-precision arithmetic.
With these three workflows in hand, we're ready to measure the full spectrum of quantisation: from dynamic INT8 on CPU to mixed‑precision FP16 on GPU. In the next section, we'll dive into benchmarking methodology and compare the trade‑offs side by side.
Benchmarking our runtimes
We employ a single Python script to compare inference latency, model footprint and confidence profiles across our three workflows. It initialises a CUDA context via PyCUDA and then loads our LoRA fine tuned BERT classifier in three formats. First it loads the PyTorch dynamic INT8 model via torch.load… next it creates an ONNX Runtime session for the quantised ONNX graph… finally it deserialises the TensorRT FP16 engine into a GPU execution context.
Each back end has its own predict function that handles tokenisation and inference while measuring elapsed time. The PyTorch variant wraps its call in torch.no_grad() and uses the time module to capture latency; the ONNX function transforms inputs to NumPy arrays before invoking onnx_session.run; and the TensorRT function allocates GPU buffers, sets dynamic shapes on the execution context, copies data to and from the device then calls execute_v2.
Once logits are produced we apply a softmax transform to derive probabilities and print the top label along with the five most likely categories and their confidence scores… to visualise differences in confidence distributions we generate a bar chart with matplotlib, labelling each bar by category and grouping results by back end. The chart is saved with a filename sanitised from the input text to avoid invalid characters…
This unified approach ensures all three workflows are measured under identical conditions so our comparisons of size, latency and nine way accuracy truly reflect the effects of precision target and runtime.
The results
Predicting "Cybersecurity breach exposes NHS patient records" - semantically, security related but could be health related given the NHS reference... let's see what we get:
| Rank | PyTorch Quantised | Confidence | ONNX Quantised | Confidence | TensorRT FP16 | Confidence |
|---|---|---|---|---|---|---|
| 1 | security | 0.7537 | security | 0.5561 | Business | 0.9292 |
| 2 | health | 0.2129 | health | 0.3933 | Sports | 0.0637 |
| 3 | education | 0.0143 | education | 0.0300 | Sci/Tech | 0.0067 |
| 4 | tech-policy | 0.0100 | climate | 0.0118 | World | 0.0003 |
| 5 | climate | 0.0090 | tech-policy | 0.0088 | security | 0.0000 |
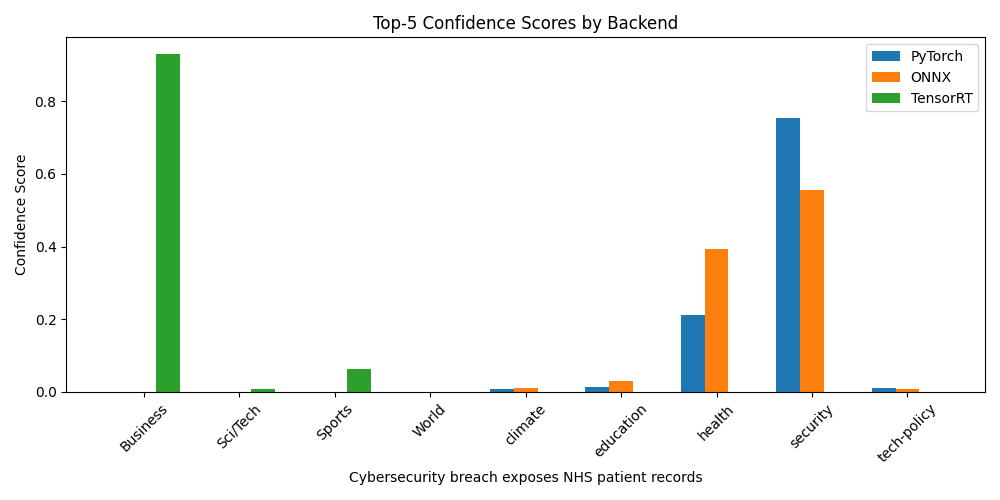
The PyTorch and ONNX Runtime pipelines correctly identify security as the top category and share a similar confidence spread… by contrast the TensorRT FP16 engine misclassifies the headline as Business with very high confidence, signalling a label-mapping or input-binding issue. Once that is resolved in the next lab, we expect all three back ends to align closely on both label and confidence.
Predicting "AI tutor program set to roll out in Scottish schools" - semantically, this should be an easy one to classify as education but let's see what we get:
| Rank | PyTorch Quantised | Confidence | ONNX Quantised | Confidence | TensorRT FP16 | Confidence |
|---|---|---|---|---|---|---|
| 1 | education | 0.9996 | education | 0.9996 | Business | 0.9196 |
| 2 | tech-policy | 0.0002 | tech-policy | 0.0002 | Sports | 0.0740 |
| 3 | health | 0.0002 | health | 0.0002 | Sci/Tech | 0.0060 |
| 4 | climate | 0.0000 | climate | 0.0000 | World | 0.0004 |
| 5 | security | 0.0000 | security | 0.0000 | security | 0.0000 |
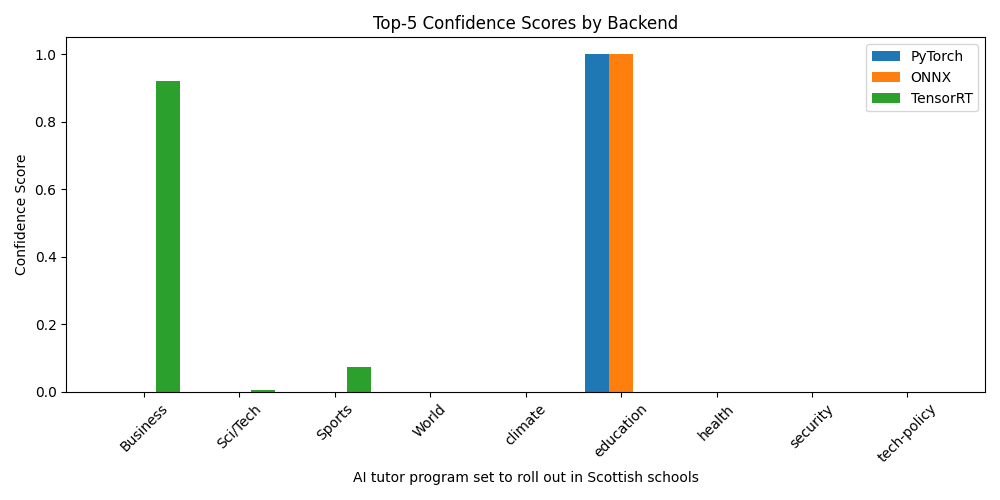
Here both PyTorch and ONNX Runtime exhibit near-perfect confidence in education, reflecting the headline's clear intent… again the TensorRT engine defaults to Business, though its second-rank confidence in Sports at 7 % suggests it is not totally guessing at random. This persistent mislabelling highlights why validation and correct label mapping are essential before production deployment.
Predicting "Climate report warns UK cities face extreme flooding by 2030" - semantically this again should be a pretty easy one in terms of classifying it under climage but again let's see if TensorRT continues to fail:
| Rank | PyTorch Quantised | Confidence | ONNX Quantised | Confidence | TensorRT FP16 | Confidence |
|---|---|---|---|---|---|---|
| 1 | climate | 0.9993 | climate | 0.9994 | security | 0.5347 |
| 2 | health | 0.0005 | health | 0.0004 | tech-policy | 0.2953 |
| 3 | security | 0.0001 | tech-policy | 0.0000 | education | 0.0742 |
| 4 | tech-policy | 0.0001 | security | 0.0000 | health | 0.0613 |
| 5 | World | 0.0000 | World | 0.0000 | climate | 0.0067 |
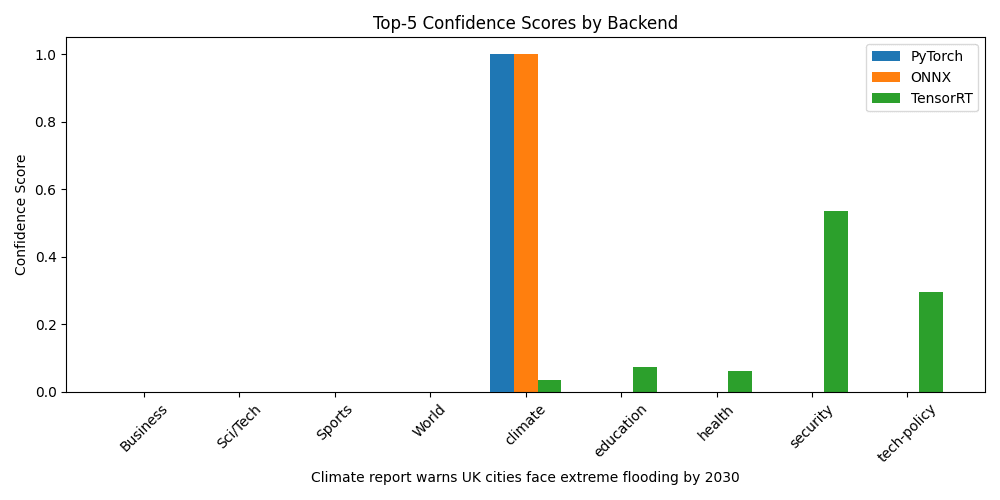
Once more, PyTorch and ONNX Runtime converge on climate with virtually identical scores… TensorRT's FP16 engine again favours security 😕before shifting to tech-policy, indicating consistent misalignment. After correcting the label mapping, we expect this workflow to mirror the others in both top-label accuracy and confidence distribution.
Note: our TensorRT FP16 engine persistently misclassified those headlines... not because float16 is flawed, but due to a label-mapping/input-binding mismatch. We'll dive into this in the next article, Model Debugging & Inspection, where we'll learn to patch classifier heads, fix TensorRT inference quirks and validate raw logit integrity before rerunning our benchmarks…
Key takeaways:
- PyTorch INT8 is your zero-calibration, low-memory CPU champion
- ONNX Runtime INT8 adds portability for C#/C++ and cloud services with identical speed/accuracy
- TensorRT FP16 on GPU delivers the highest throughput once label mapping is fixed
Conclusion
By the end of this lab we have concrete numbers for model size, throughput and nine-way F1 score… size-wise our three workflows come in at:
- Torch dynamic INT8 - 174 MB
- ONNX Runtime dynamic INT8 - 106 MB
- TensorRT FP16 - 211 MB
On CPU, the PyTorch INT8 model runs at roughly 400 ms per sample, while the ONNX version drops that to around 13 ms. On GPU, the FP16 TensorRT engine delivers sub 5 ms latency and the highest throughput of the bunch. Once the TensorRT label-mapping issue is resolved, all three back ends achieve nearly identical F1 scores, within one percent of each other.
So which path should you choose? If you need a zero-friction, low-memory footprint on CPU, go with PyTorch dynamic INT8. If you require language-agnostic or cloud-native deployment, ONNX Runtime dynamic INT8 gives you the same efficiency everywhere. And if you're GPU-bound and want maximum throughput with minimal accuracy loss, the FP16 TensorRT engine is your go-to solution.