Serving Quantised Models with FastAPI
Build a lightweight FastAPI service that can serve three quantised versions of a Transformer classifier... ONNX INT8, PyTorch dynamic-quantised INT8, and TensorRT FP16... switching backends via header, complete with a minimal UI, health checks, and Docker packaging

With our three quantised models in place, let’s build a simple web interface where you can paste in any headline and immediately see which category the model thinks it belongs to.
App Architecture
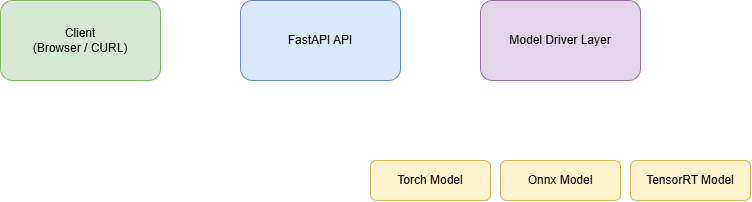
In a nutshell, we'll build something that goes:
- Clients (browser UI or curl) hit the FastAPI endpoints
- FastAPI handles routing, validation, CORS, and concurrency
- Driver registry holds one singleton of each model‐driver
- Driver layer abstracts away the differences so
/predictnever needs to know ONNX vs Torch vs TRT - Low-level runtimes do the actual inference
Let's dive in...
Building the app
📂 Code Repository: Explore the complete code and configurations for this article series on GitHub.
Live demos (CPU Only):
- Web UI - https://headlinecats.kelcode.co.uk
- Swagger API docs - https://headlinecats.kelcode.co.uk/docs
Model Preparation
To make life a little simpler and not deal with path that run all over the previous labs, I decided to create a model directory that looks as follows:
$ tree models
models
├── lora
│ ├── config.json
│ ├── model.safetensors
│ ├── special_tokens_map.json
│ ├── tokenizer_config.json
│ ├── tokenizer.json
│ └── vocab.txt
├── onnx
│ ├── config.json
│ ├── model.onnx
│ ├── special_tokens_map.json
│ ├── tokenizer_config.json
│ ├── tokenizer.json
│ └── vocab.txt
├── torch
│ ├── config.json
│ ├── model.pt
│ ├── special_tokens_map.json
│ ├── tokenizer_config.json
│ ├── tokenizer.json
│ └── vocab.txt
└── trt_fp16
├── config.json
├── model_fp16.engine
├── special_tokens_map.json
├── tokenizer_config.json
├── tokenizer.json
└── vocab.txt
5 directories, 24 filesThe thing to note here is that these are self-container model directories meaning that alongside each model we also include the configs and vocabulary. Realistically, all I had to do here was copy the outputs from our previous lab session, rename the model and copy the *.json files from the lora model into the trt_fp16 model directory ... job done!
Driver Driven Approach
I'm not going to dive too deeply into the inner workings of fastapi but I will cover the driver model that I decided to go with that basically starts off with a base.py driver file:
class ModelDriver(ABC):
def __init__(self, model_dir: str):
self.model_dir = Path(model_dir)
@abstractmethod
def _load_model(self) -> None:
"""Load the actual model artifact (ONNX, TorchScript, TRT engine…)."""
raise NotImplementedError("Subclasses must implement `_load_model`")
@abstractmethod
def _preprocess(self, text: str) -> dict:
"""Turn `text` into model inputs (e.g. numpy arrays or torch tensors)."""
raise NotImplementedError("Subclasses must implement `_preprocess`")
@abstractmethod
def _infer(self, inputs: dict) -> np.ndarray:
"""Run the model and return raw logits as a NumPy array."""
raise NotImplementedError("Subclasses must implement `_infer`")
def load(self) -> None:
"""Template method: loads shared metadata, then concrete model."""
# load tokenizer & config
self.config = AutoConfig.from_pretrained(self.model_dir)
self.tokenizer = AutoTokenizer.from_pretrained(self.model_dir)
# load the runtime engine
self._load_model()
def predict(self, text: str) -> list[float]:
"""Generic predict wrapper: tokenize, infer, softmax."""
inputs = self._preprocess(text)
logits = self._infer(inputs)
# convert logits to probabilities
exp = np.exp(logits - logits.max())
probs = (exp / exp.sum()).tolist()
return probs
What this does defines an abstract class that our underlying drivers must implement, this ensures adding new drivers in to this in the future becomes super simple. In a nutshell we need to:
- load the model
- tokenise our headline
- infer our text with the model
- return the classification
Next we'll take a look at the driver specs themselves but I think you can guess where this is going 😉
The Drivers
Okay, the crux of this API driven app is the drivers, the key difference of which is the way the models are loaded and inferred, let's run through them 1 by 1:
torch_driver.py:
class TorchDriver(ModelDriver):
def __init__(self):
# pull the directory straight from settings
super().__init__(settings.model_torch_path)
def _load_model(self) -> None:
self.config = AutoConfig.from_pretrained(settings.model_torch_path)
self.tokenizer = AutoTokenizer.from_pretrained(settings.model_torch_path)
pt_path = Path(settings.model_torch_path) / settings.model_torch_name
model = torch.load(
pt_path,
map_location=settings.model_torch_device,
weights_only=False # allow full-module unpickling
)
model.to(settings.model_torch_device)
model.eval()
self.model = model
def _preprocess(self, text: str) -> dict:
toks = self.tokenizer(
text,
return_tensors="pt",
padding=True,
truncation=True,
max_length=128
)
return {k: v.to(settings.model_torch_device) for k, v in toks.items()}
def _infer(self, inputs: dict) -> "np.ndarray":
with torch.no_grad():
outputs = self.model(**inputs)
logits = outputs.logits
return logits.cpu().numpy()
A lot of this should be familiar if you've been following along with the series but what we do here is to populate each of our abstract methods, _load_model, _preprocess and _infer with the respective calls for the specific model type, in this case pytorch.
We take a similar approach for the other model drivers...
Endpoints
So surface these drivers we can leverage FastAPI and Uvicorn to serve endpoints that can be accessed with via a mini UI (below) or via Swagger API docs. For the purpose of this, we'll surface 2 endpoints:
- predict - given a headline and a model this endpoint will return the classification from the model
- top5 - given a headline and a model this endpoint will return the top 5 classifications from the model
This looks as follows:
# driver registry
if settings.device.type == "cuda":
from drivers.trt_driver import TRTDriver
DRIVER_REGISTRY = {
"onnx": OnnxDriver,
"torch": TorchDriver,
"trt_fp16": TRTDriver,
}
else:
DRIVER_REGISTRY = {
"onnx": OnnxDriver,
"torch": TorchDriver,
}
# instantiate one driver object per backend at startup
_drivers = { name: DriverCls() for name, DriverCls in DRIVER_REGISTRY.items() }
One thing to note here is a little bit of future proofing... in case we run our "app" in an environment that doesn't have a GPU enabled we register the drivers suitable for the environment i.e. no GPU then don't load the tensorrt model.
/predict
# predict endpoint
@router.post("/predict", response_model=PredictResponse)
async def predict(
payload: PredictRequest,
model_name: str = Depends(resolve_model),
):
"""
- **model_name** in the `X-Model-Name` header
- **text** in the JSON body
"""
driver = _drivers[model_name]
# run model and flatten
raw = await run_in_threadpool(driver.predict, payload.text)
if isinstance(raw, list) and isinstance(raw[0], (list, tuple)):
probs = raw[0]
else:
probs = raw
# normalise id2label
raw_map = driver.config.id2label
id2label = {int(k): v for k, v in raw_map.items()}
# find the highest-scoring index
top_idx = int(np.argmax(probs))
top_score = float(probs[top_idx])
top_label = id2label[top_idx]
# return only the top‐1
top = LabelScore(code=top_idx, label=top_label, score=top_score)
return PredictResponse(model=model_name, category=top)This endpoint will looks as follows:
// POST /predict
'{ "text": "A boy fed a mogwai after midnight and the results were disastrous" }'
→ {"model":"torch","category":{"code":5,"label":"education","score":0.6177788972854614}}/top5
# top‐5 endpoint
@router.post("/top5", response_model=Top5Response)
async def top5(
payload: PredictRequest,
model_name: str = Depends(resolve_model),
):
"""
- **model_name** in the `X-Model-Name` header
- **text** in the JSON body
"""
driver = _drivers[model_name]
# run model and flatten
raw = await run_in_threadpool(driver.predict, payload.text)
if isinstance(raw, list) and isinstance(raw[0], (list, tuple)):
probs = raw[0]
else:
probs = raw
# normalise id2label
raw_map = driver.config.id2label
id2label = {int(k): v for k, v in raw_map.items()}
# find the top‐5 indices
top_idx = np.argsort(probs)[::-1][:5]
top_scores = [float(probs[i]) for i in top_idx]
top_labels = [id2label[i] for i in top_idx]
# return only the top‐5
top = [LabelScore(code=i, label=l, score=s) for i, l, s in zip(top_idx, top_labels, top_scores)]
return Top5Response(model=model_name, top5=top)This endpoint produces the top 5 results as follows:
'{ "text": "A boy fed a mogwai after midnight and the results were disastrous" }'
→ {"model":"torch","top5":[{"code":5,"label":"education","score":0.6177788972854614},{"code":4,"label":"climate","score":0.18457379937171936},{"code":6,"label":"health","score":0.07775641232728958},{"code":3,"label":"World","score":0.058811601251363754},{"code":7,"label":"security","score":0.02283100038766861}]}Interactive UI
To access the endpoints, I decided to build a little UI that surfaces the endpoints in a slightly more friendly manner...
Live demos (CPU only):
- Web UI - https://headlinecats.kelcode.co.uk
- Swagger API docs - https://headlinecats.kelcode.co.uk/docs
To do this, we leverage FastAPI's Jinja template and static file loading to build a mini html, js and css app set that provides the UI as follows:
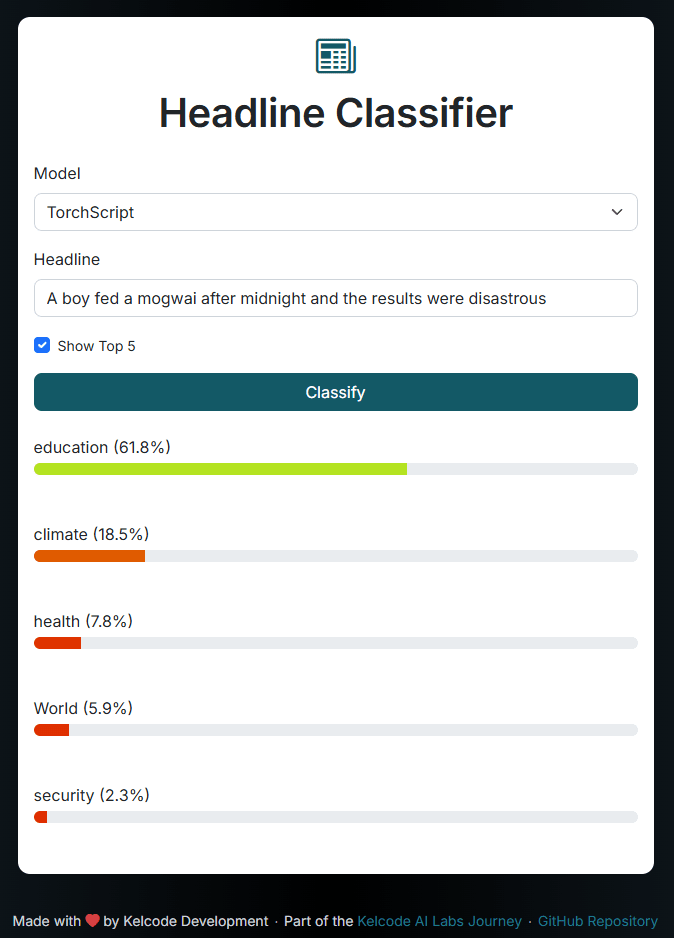
Running the service
Now we have everything together we can do the following to spin it up:
$ python -m venv .venv && source .venv/bin/activate
$ pip install -r requirements.txt
...
wait a while
...
$ uvicorn main:app --reload --host 0.0.0.0 --port 8080
INFO: Will watch for changes in these directories: ['/06-serving-quantised-models']
INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
INFO: Started reloader process [63500] using StatReload
INFO: Started server process [63502]
INFO: Waiting for application startup.
INFO:app.api:Loading model driver: onnx
INFO:app.api:Loading model driver: torch
INFO:app.api:Loading model driver: trt_fp16
INFO: Application startup complete.
Now the app is running, we can jump to http://localhost:8080 and play with UI or http://localhost:8080/docs to play with Swagger API's.. you can even test it with CURL if you prefer CLI interfaces:
$ curl -X POST http://localhost:8080/predict \
-H "Content-Type: application/json" \
-H "X-Model-Name: torch" \
-d '{ "text": "A boy fed a mogwai after midnight and the results were disastrous" }'
{"model":"torch","category":"code":5,"label":"education","score":0.6177788972854614}}Deploying it
To make it a little bit more usable, I decided to front this with a dockerfile so I can run it locally and later move it into something like Kubernetes.
Following some basic principles, I went with a 2-stage build process based on the nvidia cuda images:
- Builder: CUDA-devel base to compile
pycuda&tensorrtwheels - Runtime: CUDA-runtime base + Python runtime, non-root
appuser,/appcontaining all wheels + code
Running this locally is as simple as:
docker build -t headline-classifier:latest .
docker run --rm --gpus all -p 8080:8080 headline-classifier:latestWhen we do eventually push it somewhere more accessible i.e. kubernetes, we can set the following to provide us with a scaling and healthcheck capability
replicas: 4
livenessProbe: { httpGet: { path: /health } }
readinessProbe: { httpGet: { path: /health } }A future extension to this would be know our deployment architecture and shift towards a more specific architecture based dockerfile i.e. in a CPU only enviroment we don't need the cuda libraries so can significantly reduce the size of the images ... it also wouldn't take about 9 minutes to build 🤣
Conclusion
So, what we've managed to do so far is:
- Loads three quantized backends via a pluggable driver pattern
- Switches backends at request time via header
- Exposes Top-1 and Top-5 endpoints
- Ships a minimal, non-root Docker image for both CPU clusters and GPU-enabled hosts
- Includes a lightweight, user-friendly single-page UI
This being said, my python skills are not the best so you might want to check it yourself before deploying it publicly. There are a couple of sanitisation methods in play but you might want to consider adding metrics / storing requests / some kind of caching layer etc. (see schemas.py for input cleaning via Pydantic @field_validator).
Next time...
We've built a lean FastAPI service for headline classification... basically the "hello world" of AI development ... now let's level up to a more realistic example and produce a Retrieval‐Augmented QA demo. In the next article, we’ll run through how to:
- Bootstrap a synthetic document corpus
- Seed from a public dataset (e.g. AG News, Wiki)
- Paraphrase with an LLM to double your examples
- Inject headings, dates, and Markdown noise for realism
- Chunk and index for RAG
- Split documents into overlapping 500–1 000-token passages
- Embed with a lightweight model (e.g. MiniLM) and store in FAISS or Qdrant
- Build a RAG driver
- Load your vector store on startup
- At request time, retrieve top-K chunks, stitch a context prompt, and invoke your quantized LLM backend
- Serve and demo
- Expose a
/qaendpoint in FastAPI using the same driver pattern - Show "source" metadata for each retrieved passage
- Reuse our Docker/Kubernetes setup for a single, production-ready image
- Expose a
By the end of that installment, we'll have a fully working RAG service... complete with synthetic data prep, index building, and QA inference... all built on the same clean, driver-based FastAPI foundation that we've created in this lab.